RabbitMQ之shovel插件使用介绍
rabbitmq 之 shovel插件使用介绍
shovel插件主要功能
A shovel can move messages between brokers (or clusters) in different geographic or administrative domains that
翻译成人话,就是shove这个玩意是用来在broker之前或者集群之前来移动、搬运消息的,在不方便做集群复制,或者不方便使用程序进行消息转发时使用。
Shovel是分布式消息传递工具包中的一种极简但灵活的工具,可以容纳许多用例。
以下是官网列举的四项功能:
- may have different loosely related purposes
- may run on different versions of RabbitMQ
- may use different messaging products or protocols
- may have different users and virtual hosts
翻译成人话就是:
- 可以应对不同的平台进行消息传递,藕合性低。
- 可以在RabbitMQ的不同版本上运行,兼容性强。
- 可使用不同的消息传递产品或协议。
- 可使用不同的用户和虚拟主机进行传输对接,包容性好。
shovel 插件工作原理
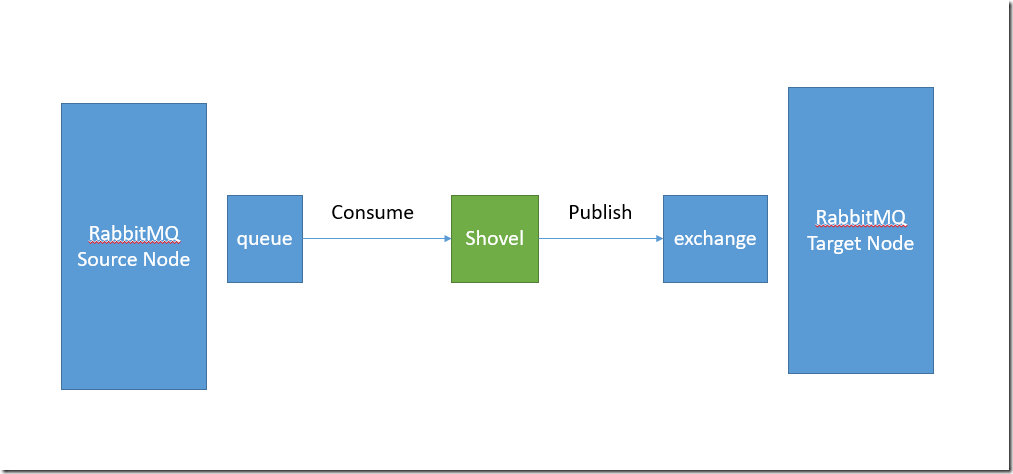
Shovel是RabbitMQ的一个插件,这个插件的功能就是将源节点的消息发布到目标节点,这个过程中Shovel就是一个客户端,它负责连接源节点,读取某个队列的消息,然后将消息写入到目标节点的exchange/queue中。根据这么一个概念,其实也可以自己开发一个简单的程序,负责从一个节点读取数据然后发送到目标节点。
shovel 如何使用
In essence, a shovel is a minimalistic message pump. Each shovel:
- Connects to the source and destination clusters
- Consumes messages from a queue
- Re-publishes to a destination
- Uses data safety features on both ends and handles failures
本质上,shove就像一个消息泵,它主要做了以下的事情:
- 连接集群源节点和目标节点
- 从队列中消费消息
- 重新发布消息到目标节点
- 在两端使用数据安全功能保障数据安全,并处理故障
只要进入rabbitmq后台,安装:
rabbitmq-plugins enable rabbitmq_shovel
这个插件,就可以使用了。
如果你需要在rabbitMQ控制台去配置,则还需要开启rabbitmq_shovel_management 这个插件。
rabbitmq-plugins enable rabbitmq_shovel_management
https://cloud.tencent.com/developer/article/1469332
注意,源节点和目标节点都安装此插件。
shovel插件使用场景
生产环境中会遇到RabbitMQ数据迁移的场景,例如:切换云服务厂商、不同Region之间数据迁移、新搭建RabbitMQ实例,数据需要同步至新的RabbitMQ实例。
https://www.cnblogs.com/middleware/p/9959221.html
https://zhuanlan.zhihu.com/p/30588183
shovel 插件确认ack消费慢的问题
由于在使用过程中,发现shove作为消费端消费时,速度远不如普通的消费端的消费速度,一直处在2000/s 左右,如果mq inbound 速度大于2000/s,就会很容易产生堆积。
这个问题找了好久,困了我一上午,最后在google上找到一老外的回答,解决了我的问题!!!!
老外就是牛逼!!!!
有个老外也遇到我的问题,在网站上提问说:
Hi!
My setup includes a rabbitmq-c application that publishes messages on node A.
The publishing rate is about 200mps, each message can be up to 10Kb.Shovel (node A) is configured to move them to node B.
On node B i’m dequeuing the messages with a PHP test script with $queue->get(AMQP_AUTOACK).
If i keep the publishing rate at 200mps then i can see that the queue on node A is empty and the Q on node B is
filling up. The read-rate of my test script is really low.If i stop the publishing, 3-5 seconds later, my test script starts reading like crazy until the queue on node B is empty.
Even If I slow down the publishing rate to 5mps , same is happening , messages are piling up on node B until i dial down the pressure.
This problem disappears if I set ack_mode to on_publish or no_ack. In this case the reader script reads with the publishing speed.
大意就是,我特么用这个shove插件,消费速度慢得一逼,这插件真JB垃圾,巴拉巴拉。。。。。
最后有个管闲事的老外给了他正确的回答:
Hi. If the shovel is on node A then {ack_mode, on_publish} is not
particularly safe - if the network connection goes down then you will
lose messages that were on the wire.If the shovel were to be running on node B then {ack_mode, on_publish}
would be safer, as it would tolerate network failures (but not a crash
at node B).on_confirm would still be better. Of course, since you’re consuming in
autoack mode in the php script you can lose messages there anyway…You didn’t say which version of RabbitMQ you were running. The script
seems perfectly reasonable (I assume that you are not doing anything
AMQPish in the part elided by “/* do stuff here, count messages, run mps
stats etc… */“).So it’s a bit of a puzzle. If confirms + persistence are so much slower
than persistence alone, then I wonder if somehow you have a machine that
fsyncs very slowly, since that’s the primary difference in what node B
will be doing.Cheers, Simon
大意就是,你个SB,你用错了!!!
解释了一通两个模式的意义,也就是我应该使用 ack_mode on_publish模式。而铲子放在哪个节点上的意义也不一样,如果铲子放在A节点上,从A—>B节点,那么它就不是安全的连接,不能完全保证信息不丢失。
如果铲子放在B节点上,从A—>B,则是安全模式,它可以容忍网络故障,不会使应用程序崩溃。
shovel插件与federation插件区别
shove是做消息迁移的,federation是分流消费的。
具体请查看federation的使用
